
Predictive maintenance strategies for manufacturing

Predictive maintenance allows to plan maintenance more efficiently and reduce downtime due to broken parts or unnecessary maintenance costs.
Traditionally, maintenance was done by reactively fixing or replacing parts after they broke down. In addition, preventive maintenance was used by changing and maintaining parts before they could break down. Developments towards Industry 4.0 and advancements in Internet of Things have introduced the concept of predictive maintenance which allows to plan maintenance more efficiently and reduce downtime due to broken parts or due to maintenance work which is not actually needed.
When dealing with equipment of every kind, there are failures sooner or later during its lifetime. These failures typically happen due to internal wear or by outside conditions not suitable for the equipment. There are several ways to deal with or prevent failures.
One way is to look at the scale consisting of different maintenance strategies. One side of it, we have a strategy where we react to the failures after they happened. On the other side, it is the opposite; we do everything to prevent equipment failure before it occurs.
One technique to deal with equipment failure is to wait until it happens and then fix it. This is known as reactive maintenance (or run to failure maintenance). Depending on the equipment and its use case, this might be a good enough solution, however, often machine downtime leads to a high financial loss. It is also possible that the failure of one part can start a chain reaction of other assets parts breaking.
Another common practice is applying preventive maintenance where the equipment is being regularly serviced based on a schedule. This schedule is created by examining the statistics of previous failures on different parts of the equipment. In this instance, a pessimistic approach is typically adopted. Although helping to achieve less downtime and increasing the lifetime of the asset; simultaneously it is increasing maintenance costs.
Why? Because preventative maintenance is often done more times than is necessarily required.
There is a middle ground between these two approaches. In the case of predictive maintenance, we monitor the behavior of the system and anticipate failures before they occur. Predictive maintenance enables just-in-time workflows, where servicing can be executed only when it is needed. It exponentially reduces downtime compared to reactive maintenance and hence reduces maintenance costs that would occur when adopting preventive maintenance.
These maintenance strategies can be visualized below as a PF-curve, where on the horizontal axis we can view time, and the vertical axis depicting the asset’s condition.
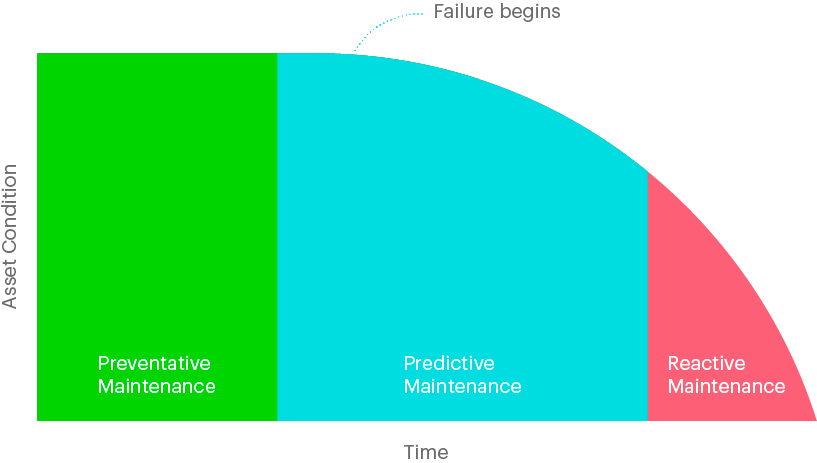
The maintenance strategy is a combination of several techniques, and for different assets, the chosen techniques can appear different, depending on the complexity and use case of the equipment.
When we have an asset for which downtime means substantial financial losses, a major effort should be placed on predictive maintenance strategies; reducing the number of maintenance works suggested by preventive maintenance, whilst avoiding failure of the system. Alternatively, some equipment may be cheap and thus quickly replaced, in which case reactive maintenance should be sufficient, as there is no need for investments in predictive maintenance.
Choosing and developing the best set of techniques for each asset can be quite complicated, but reducing maintenance costs and downtime losses can be achieved by increasing the uptime of the device.
In this article, we consider only predictive maintenance in greater detail, as reactive and preventive maintenance strategies are already quite mature and are often used within the manufacturing industry.
Predictive maintenance
Predictive maintenance can be utilized in several ways, depending on available data. Here we examine the predictive maintenance techniques from the perspective of a data scientist. This allows us to look at different modeling solutions and describe what results could be achieved with each of them.
Anomaly detection
Anomaly detection enables us to notice deviations from normal behavior and notify relevant personnel about it. These models are relatively easy to develop, and there is no need for logged failure or maintenance events. The optimal thing about this is that it can also identify abnormal behavior that hasn’t occurred before.
The simplest version of this can be done by manually setting a threshold for different data sources. This requires good domain knowledge about the problem, whilst it is only able to detect some predefined anomalies. The challenge with this approach is that it’s hard to describe what the relations between different data sources should be.
By using machine learning, we can identify multiple data sources simultaneously and let the algorithms learn the normal behavior and relations between different data sources. Thus leading to automatic detection of abnormalities, without the need for defining anomalies and thresholds beforehand.
The problem with anomaly detection is that it can produce warnings and notifications when there is nothing wrong with the equipment. New behavior for the algorithm might seem like an anomaly, as it has not seen this kind of behavior before. Therefore, the feedback system should be created, allowing users to provide feedback on whether the notification was an abnormal behavior of the device or merely a normal behavior under unseen circumstances.
Anomaly detection systems are not able to determine the exact fault source but can provide hints to an expert where the problem would be located. An expert can then examine the history of the equipment by looking at the machine data to determine where the problem might originate.

Binary classification
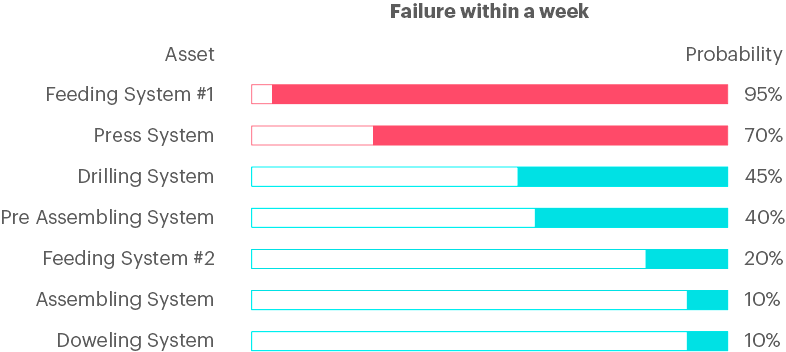
Binary classification tasks give answers to true or false type questions. Therefore we can ask whether a particular part will fail within some period, for example, a week. Depending on the algorithm used, the probability of failure within that time window could be realized. This approach is beneficial for determining the task list for the maintenance crew for the next period.
Binary classification requires historical data from our equipment, but also a log of failures. The problem with this approach is that the model needs several failures of the same type before it learns enough to begin accurately predicting this failure type. Therefore, this approach could not predict failures that haven’t occurred before. It is also harder to develop models for this problem type.
Multi-label classification
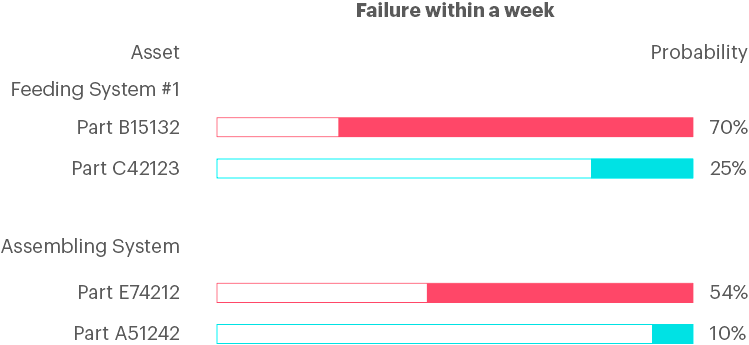
Multi-label classification is similar to the binary classification, but instead of asking only true or false questions, we can ask several questions. One way would be to define time windows and classify in which time window it is most probable that the asset will fail. Another possibility is to predict which type of failure, or for which part of the asset will occur within a time window, for example in a week.
The data needed for multi-label classification is the same as for binary classification. Developing this type of classification solution requires a little more effort than developing binary classification solutions.
Regression
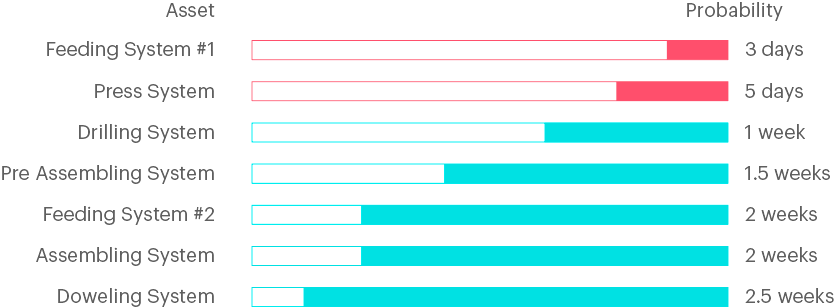
With regression algorithms, it is possible to predict the remaining useful lifetime (RUL) for equipment or its parts. This would allow creating a solution where it’s possible to list all the assets and sort them based on how long will they have until failure. The maintenance crew can then view the list and prioritize their work accordingly.
Regression tasks need the same kind of data as classification tasks, yet it is much more challenging to develop an accurate model. Typically, the problem is due to a lack of failure data.
How to start with predictive maintenance?
Although fully-fledged predictive maintenance solutions can appear expensive, it makes sense to begin with smaller steps and proof of concept type projects. Thus, gaining insights and improvements quite early on with relatively low cost.
Not all failures can be predicted ahead of time, and it is not always essential to know when things will fail. Therefore, before starting with predictive maintenance, we should ask whether the problem is of predictive nature at all? Whether we could do something useful by predicting anomalies or failure times? Or whether it is possible to collect necessary data?
We can look at these questions in more detail with the possible data sources we utilize in predictive maintenance.
Questions to ask before development
What problem needs solving?
A company in need of predictive maintenance should first ask “Which problem is the most urgent one?” For example, this could be that we want to predict whether asset X will fail within two weeks so that we could plan the maintenance work and related downtime.
Do we have relevant data sources?
After we have defined the most critical problem to solve, we should understand whether we can collect relevant data from the equipment. We might find that the asset does not have the necessary sensors and we might have to install external ones. This may include introducing a Computerized Maintenance Management System (CMMS) for collecting data about maintenance works and failures.
Is data accurate?
The quality of predictive maintenance algorithms is dependent on the quality (and often quantity) of data. Therefore, we have to ensure that collected data is accurate and measurable. For example, we have to ensure that every maintenance work and failure can be logged in to CMMS. For some sensor data, e.g. vibrational data, it is vital that sampling frequency is high enough for solving the problem.
Can we connect different data sources?
After we have made sure that we have all the necessary data sources and they are accurate enough, we also have to ensure that we can connect this data. For example, we could match the logged failures from CMMS to the sensory data of our asset.
Have we collected enough data?
Last, but not least, we should have enough data, so the machine learning algorithms could learn to generalize. For example, we might want to apply anomaly detection for a crane in a harbor, in which case we would need at least a year’s worth of data to capture the minimum amount of weather seasonality, that might affect the results.
For predicting the failure times, we would need to gather data from tens or hundreds of failures, to make sure the correct patterns are learned.
Types of data sources
The data used for developing predictive maintenance solutions not only comes from the equipment itself. Collecting and integrating additional data is not only beneficial for improving maintenance but can help find new strategies for optimizing and further improving the whole production workflow.
Operational data
The operational data from our assets is critical to understand the current situation of the equipment. This type of data might technically be the hardest to collect, as it often has to be measured very frequently, meaning that the amount collected proliferates. There may be a need for installing additional sensors. Therefore the emphasis should be put on finding out what data is really needed, and how often it should be recorded.
Asset specifications
In addition to operational data, it is beneficial to have data about capabilities, model numbers, production dates, and other asset specifications. Although this might not always be used in machine learning algorithms, it is crucial for developers and data scientists for developing the solution.
Failure history
If we want to predict the failure times of the asset or its part we need to log the failures of equipment or their parts. For this, Computerized Maintenance Management Systems (CMMS) are often used. To make this kind of data understandable to computers, we minimize the amount of free-form text and explanations about the failures. Hence, failure categories should be introduced.
Maintenance history
It is also essential to collect data about the history of maintenance work, including lubrication works and change of components. This data is typically stored and managed by CMMS. Like collecting failure history, it is vital to create and assign categories for each work item.
Operating conditions
The environment in which the asset is usually working has an impact on its behavior. Therefore the information about the surrounding environment should continuously be collected. This kind of data might include location, humidity, or temperature. For devices situated outdoors, this information might be gathered and estimated from surrounding weather stations, in which case, the weather predictions could also be introduced into predicting future behavior.
Operator attributes
Some types of devices are very dependant on how they are being operated. Therefore collecting data about who is operating the device of interest might become beneficial for predicting failures or anomalies.
Summary
Financial losses caused by the downtime of an asset can be reduced using predictive maintenance. It requires higher initial investments but will provide a greater understanding of the asset’s condition, improving the whole production and maintenance planning process.
Before predictive maintenance is applied, we integrate different data sources and start collecting data. Moving forward it is possible to begin developing predictive maintenance solutions, starting with simpler ones, like anomaly detection. This is done by taking small (and therefore cheaper) steps initially, and iteratively building a more complicated solution.
Want to know how predictive maintenance can optimize your costs? Share your challenge with us













